🎯 The Big Picture🎯 大白话版结论
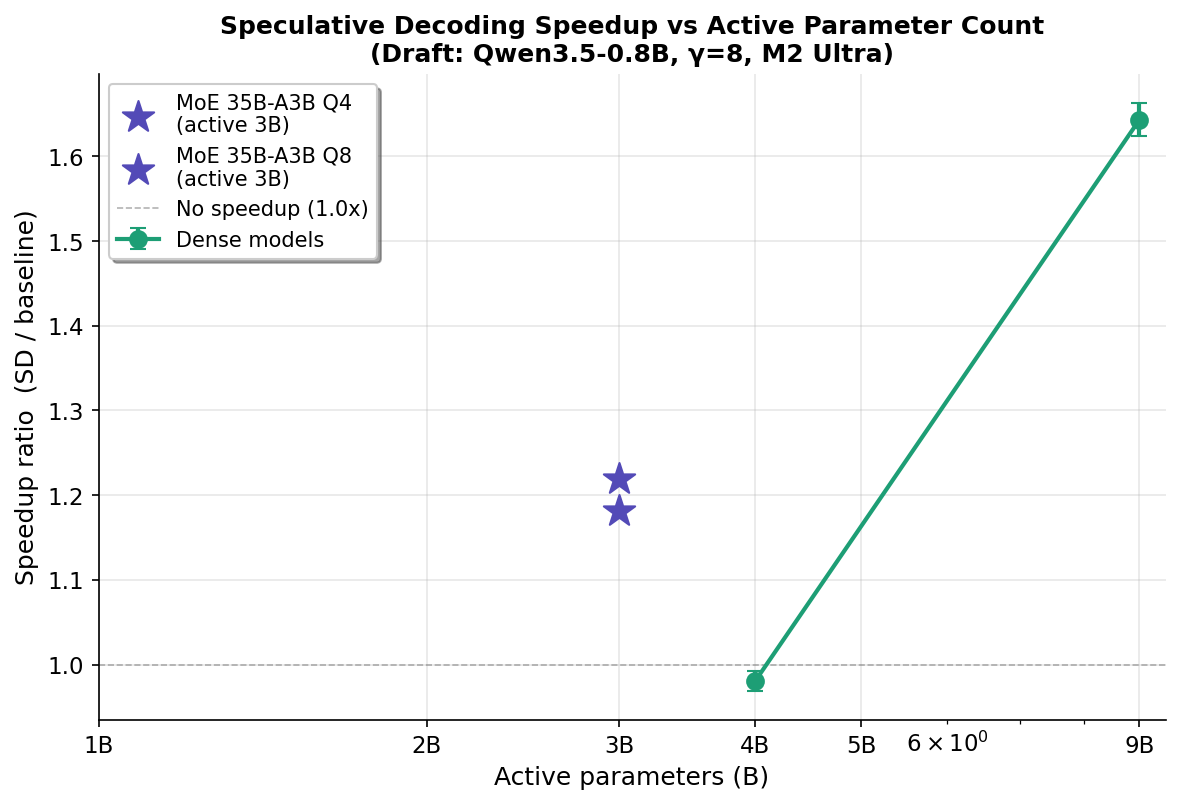
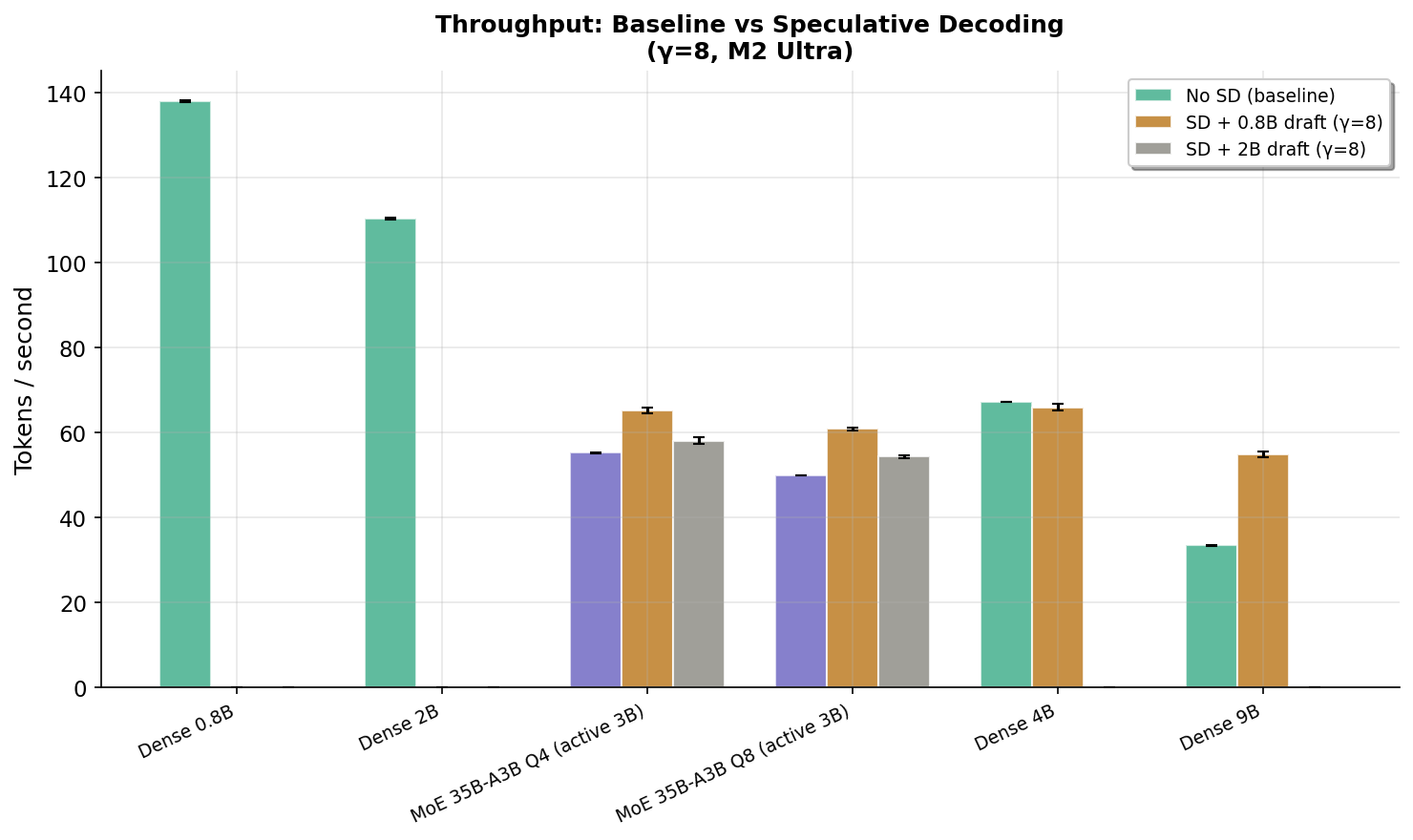
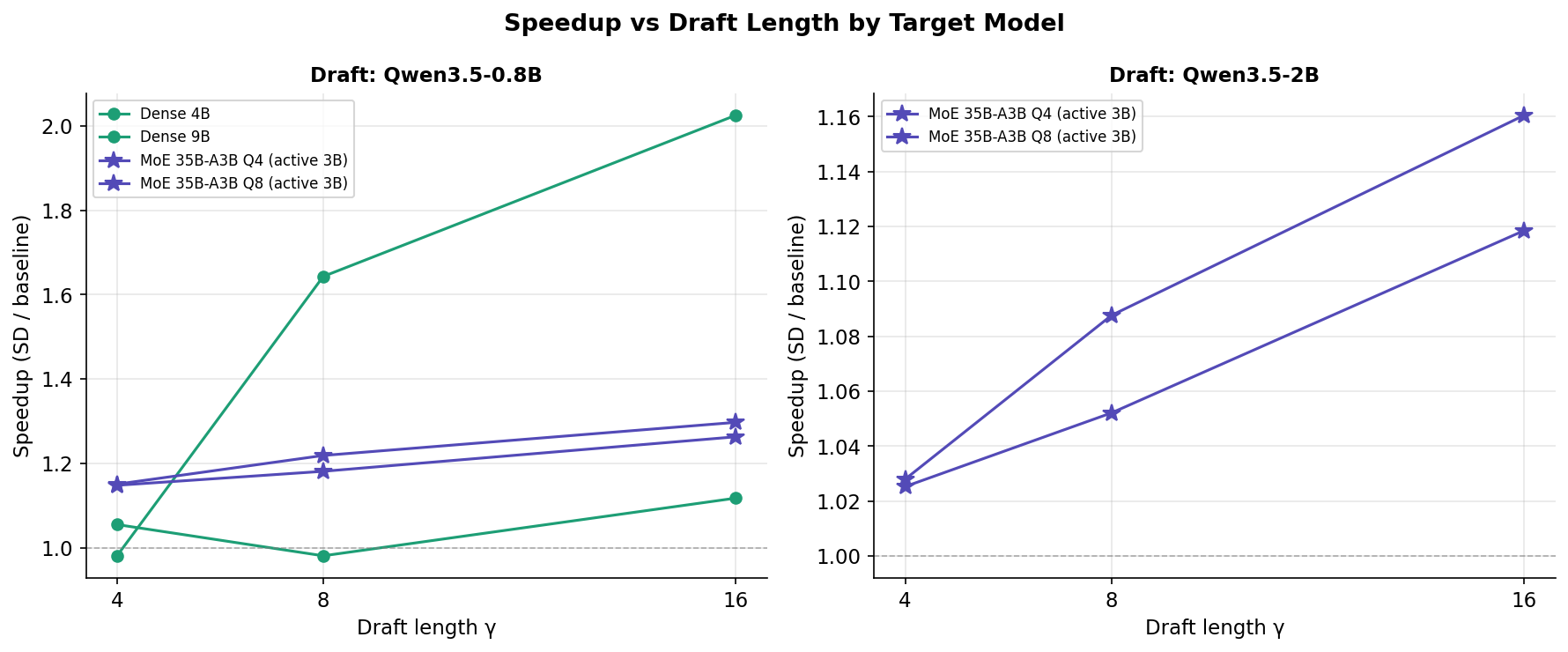
Speculative decoding (SD) uses a tiny "draft" model to guess what a big model will say, then the big model checks all the guesses at once. Usually this works because the draft gets many guesses right. But when the draft is tiny (0.8B) and the target is huge (35B MoE), almost none of the guesses are correct (<4%). So why does it still speed things up by 18–30%?
The secret: checking 16 wrong answers at once is still faster than generating 1 answer at a time. The big model has to load all 35 billion parameters from memory for each answer. When it checks 16 draft tokens in one batch, it loads those weights once instead of 16 separate times. This "batch verification amortization" saves memory bandwidth — which is the real bottleneck for MoE models.
推测解码(SD)的原理是:用一个小模型先"猜"大模型接下来要说什么,然后大模型一次性检查所有猜测。通常它能加速是因为小模型猜得准。但当小模型很小(0.8B)、大模型很大(35B MoE)时,几乎所有猜测都是错的(正确率不到4%)。那为什么还能加速18-30%?
秘密在于:一次性检查16个错误答案,仍然比一个一个地生成答案要快。大模型每生成一个token都要把350亿参数从内存里读一遍。当它一次性检查16个草稿token时,这些参数只需要读一次而不是16次。这种"批量验证摊销"节省了内存带宽——这才是MoE模型真正的瓶颈。
🗣️ Plain-Language Q&A🗣️ 大白话问答
Q: What is MoE, and why is it special?问:什么是 MoE?有什么特别的?
MoE = Mixture of Experts. Imagine a company with 128 specialists (experts), but for each task, only 2 of them actually work on it. The model has 35 billion total parameters (all 128 experts), but only uses ~3 billion per token (the 2 active experts). This makes it smart like a 35B model but fast-ish like a 3B model. The catch? All 128 experts still need to sit in memory, even if most are idle. That's a lot of data to keep around.
MoE = 混合专家模型。想象一个公司有128个专家,但每个任务只让其中2个人干活。这个模型总共有350亿参数(所有128个专家),但每个token只用到约30亿参数(2个活跃专家)。所以它聪明得像350亿的模型,但速度接近30亿的模型。问题是:即使大部分专家在"摸鱼",他们也都得坐在内存里占位子。这很费内存。
Q: Why does SD help if the draft model gets everything wrong?问:小模型猜得全错,为什么还能加速?
Think of it like a delivery truck. Without SD, the truck makes 16 separate trips, loading all the goods each time. With SD, the truck loads once and delivers 16 packages in one trip — even if all packages are returned (rejected). The savings come from loading the truck once instead of 16 times, not from delivering the right packages. For MoE models, "loading the truck" = reading 35B parameters from memory, which takes ~18ms. Doing this once instead of 16 times saves huge time.
想象一辆送货卡车。没有SD时,卡车要跑16趟,每趟都要装满货物。有SD时,卡车装一次货就跑一趟送16个包裹——即使所有包裹都被退回(拒绝)。省时间的原因是只装了一次货,而不是装16次,跟包裹是否被签收没关系。对MoE模型来说,"装货" = 从内存读取350亿参数,每次约18毫秒。读1次而不是16次,省了大量时间。
Q: Why does a smaller draft model work better than a bigger one?问:为什么更小的小模型反而更好?
The 0.8B draft outperforms the 2B draft because neither guesses correctly anyway — both have <4% accuracy. But the 0.8B model runs 2.5× faster, so the "wasted" time on drafting is much smaller. Since the speedup comes from batch verification (not correct guesses), you want the draft to be as cheap as possible. Think of it as: if you're hiring someone to make guesses that will all be wrong anyway, hire the cheapest one.
0.8B小模型比2B小模型效果更好,因为反正两个都猜不准——准确率都不到4%。但0.8B运行速度快2.5倍,所以"浪费"在猜测上的时间少得多。既然加速来自批量验证而非正确猜测,你当然希望猜测过程越便宜越好。打个比方:如果你要雇人来猜答案但猜的肯定都是错的,那就雇最便宜的那个。
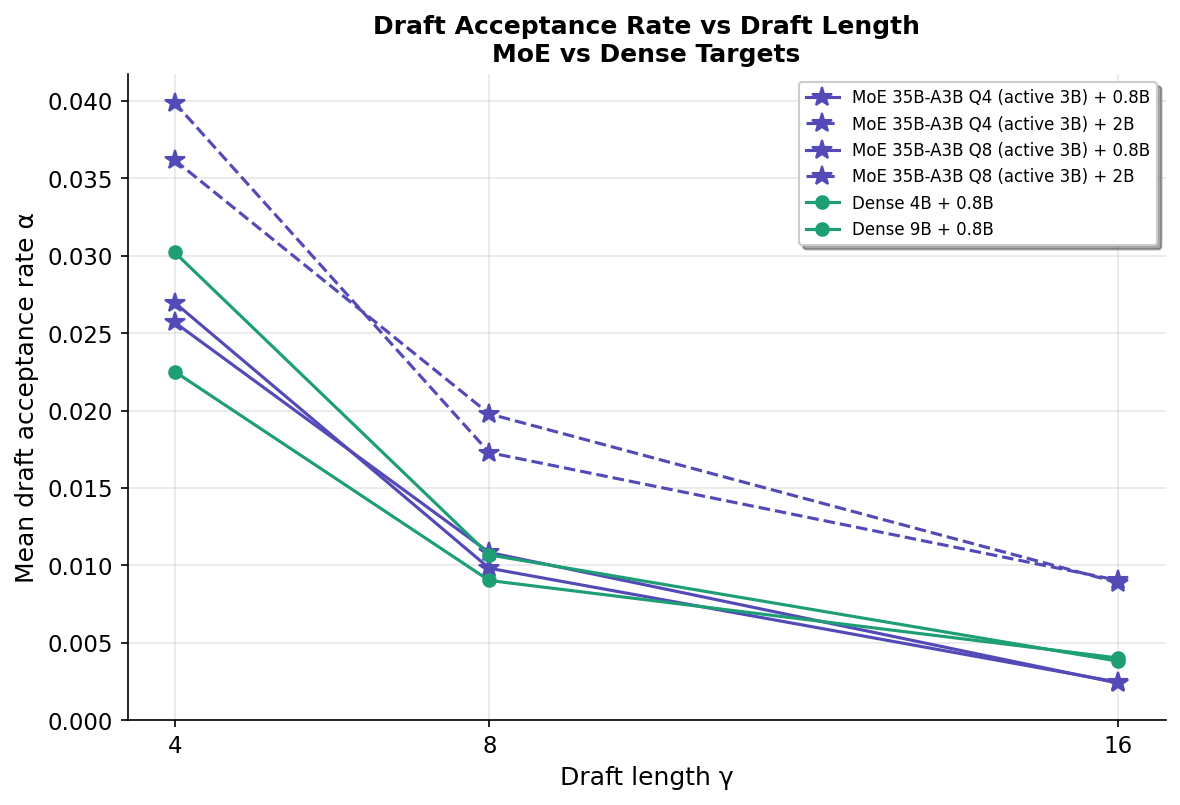
Q: Why does guessing more tokens (larger γ) give better speedup?问:为什么猜更多token(更大的γ)反而更快?
Counterintuitive, right? Guessing 16 tokens has a lower acceptance rate (0.2%) than guessing 4 tokens (2.6%). But the cost of verifying 16 tokens is NOT 4× the cost of verifying 4 tokens — it's maybe 1.5× thanks to GPU parallelism. So you get to "skip" more sequential forward passes for a relatively small extra cost. The truck analogy again: whether you put 4 or 16 packages on the truck, the fuel cost is almost the same because the heavy part is driving the route, not carrying the packages.
反直觉吧?猜16个token的接受率(0.2%)比猜4个(2.6%)低得多。但验证16个token的成本不是验证4个的4倍——得益于GPU并行计算,可能只是1.5倍。所以你用少量额外成本"跳过"了更多的逐个生成步骤。还是卡车的例子:不管你放4个还是16个包裹,油费几乎一样,因为费油的是跑路线这件事,不是搬包裹。
Q: Should I actually use this? What's the practical takeaway?问:我实际使用MoE模型时该怎么做?
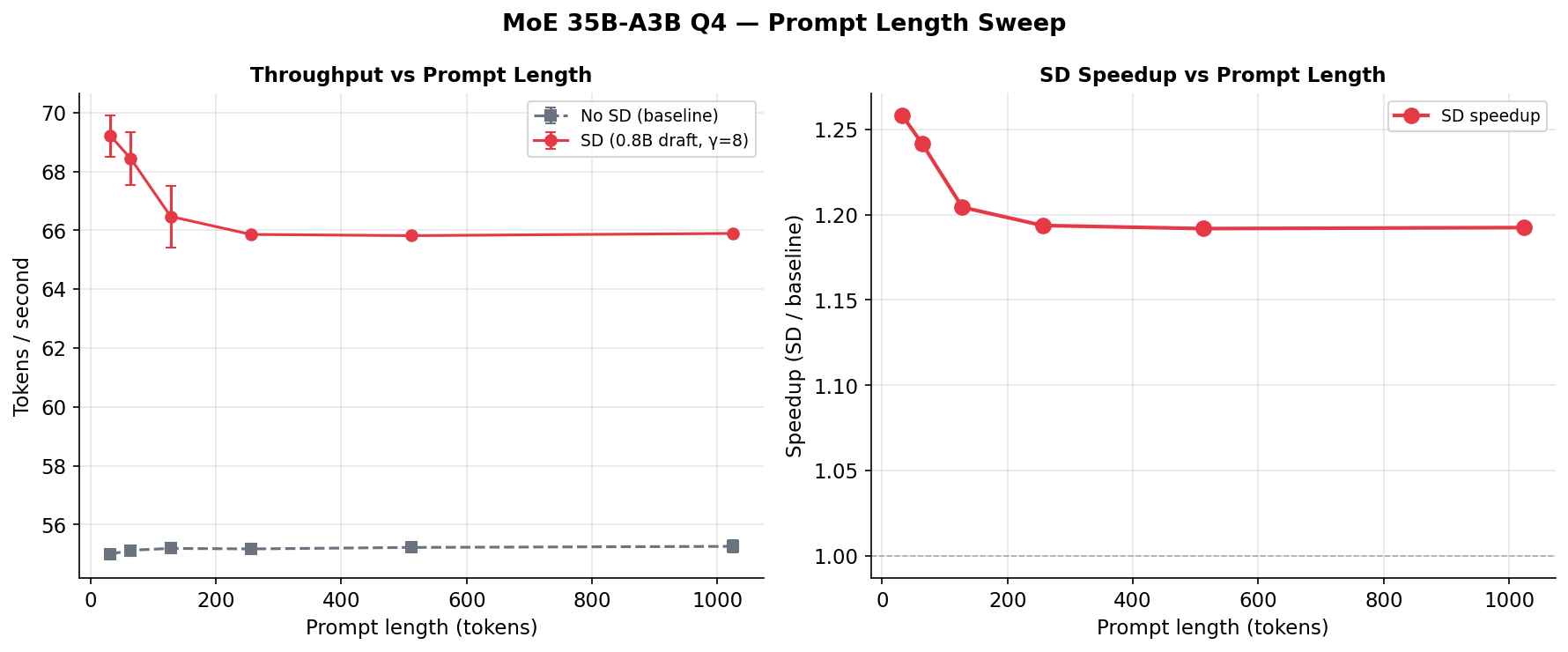
Yes! If you're running an MoE model like Qwen3.5-35B-A3B on your Mac (or similar unified-memory hardware), enable speculative decoding with the smallest draft model you have (0.8B) and set γ=16. You'll get ~26–30% faster generation for free — no quality loss, minimal extra memory (~1 GB). It's basically a free lunch.
当然用!如果你在Mac(或类似统一内存硬件)上跑MoE模型如Qwen3.5-35B-A3B,开启推测解码,用最小的草稿模型(0.8B),设γ=16。你会免费获得约26-30%的加速——不损失质量,额外内存开销很小(约1GB)。这基本上是白送的午餐。